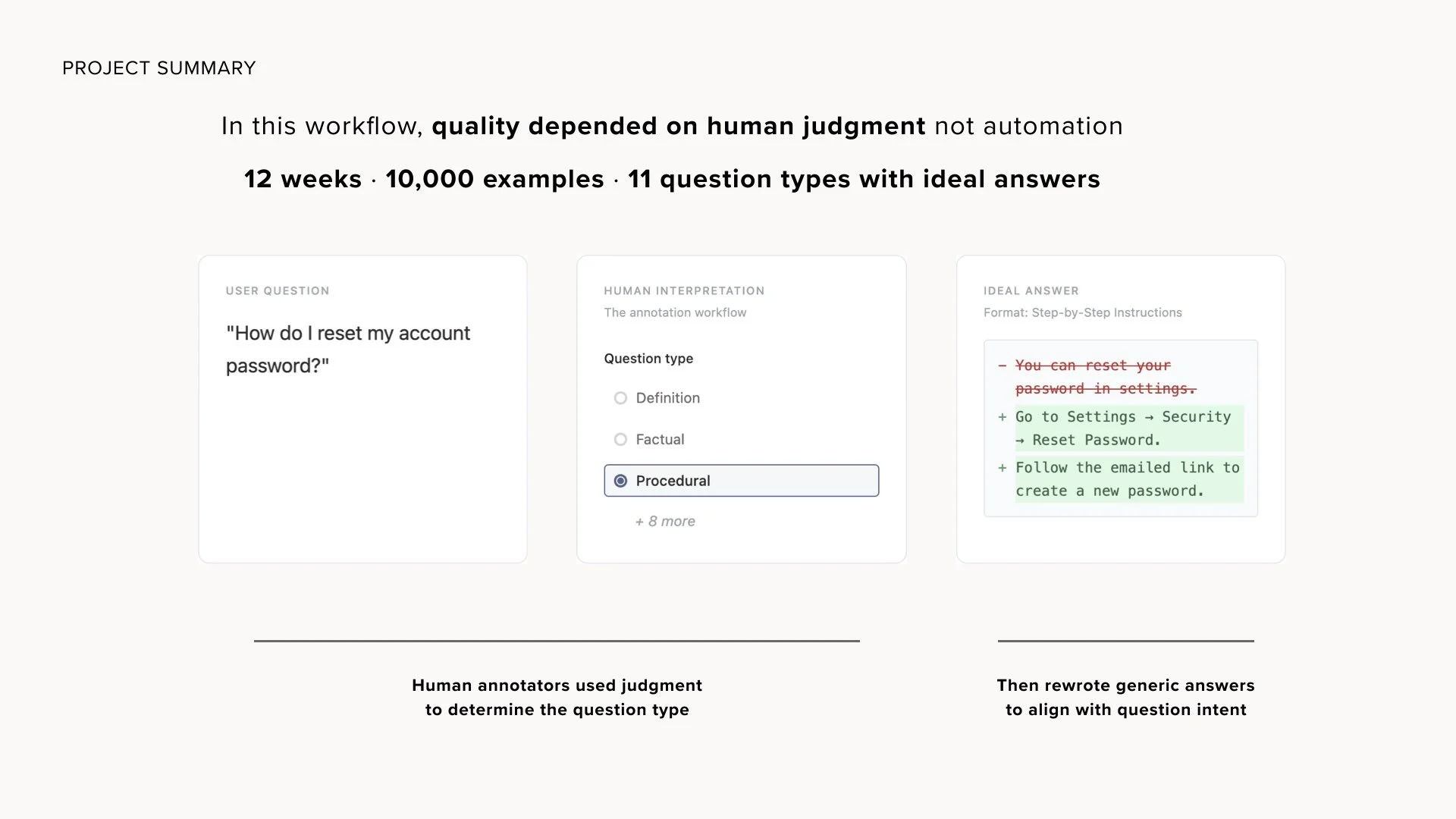
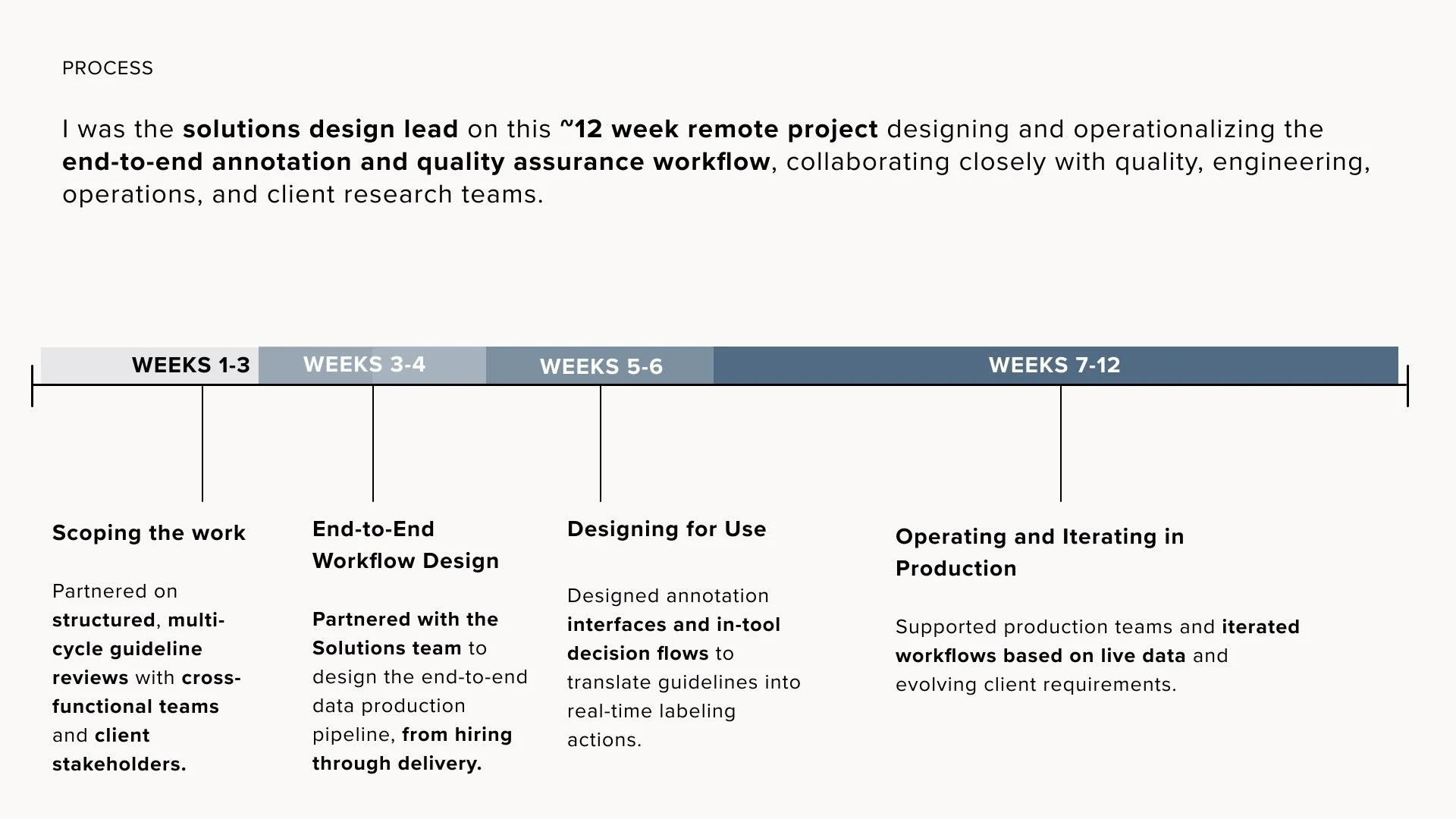
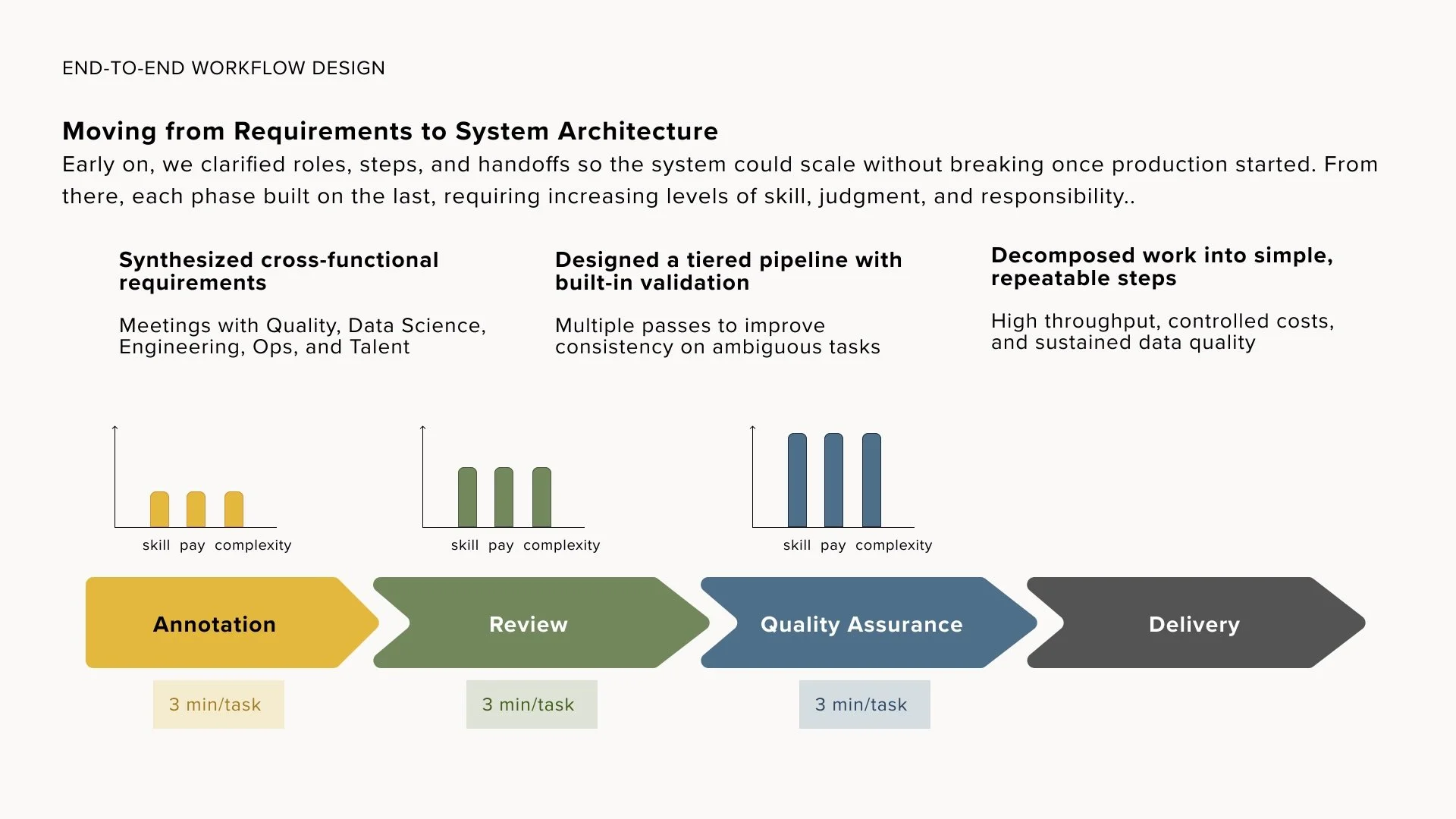
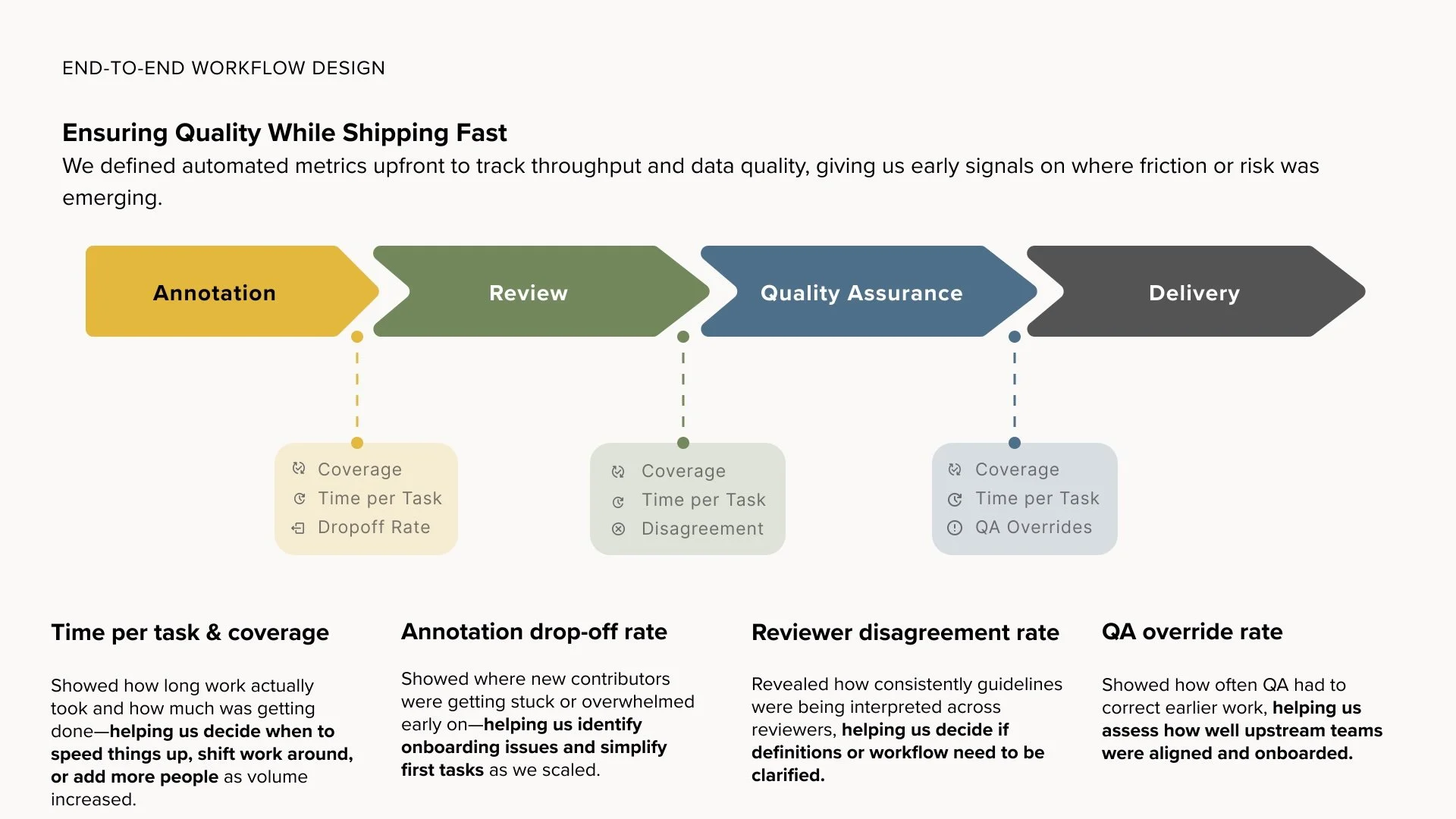
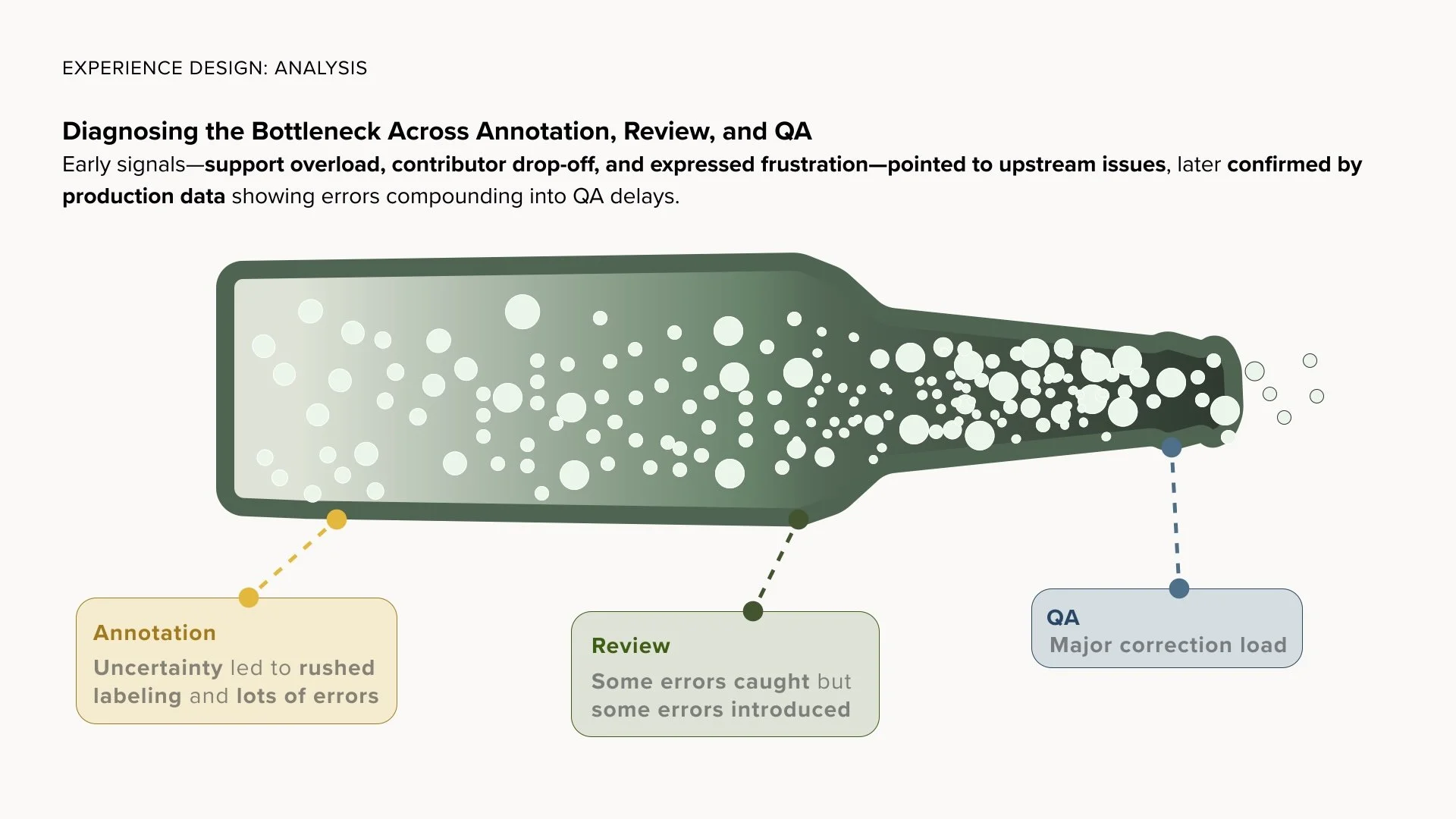
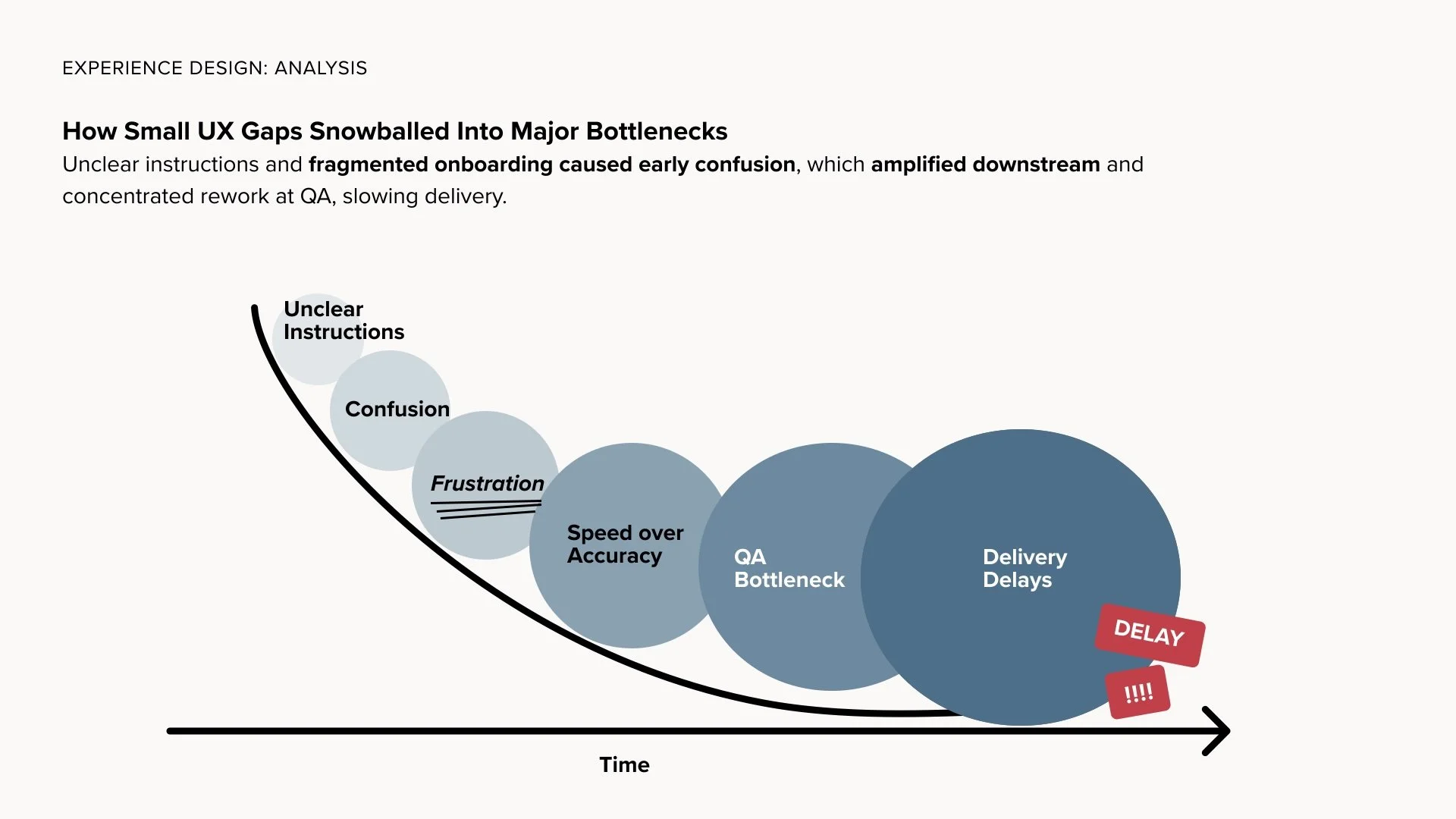
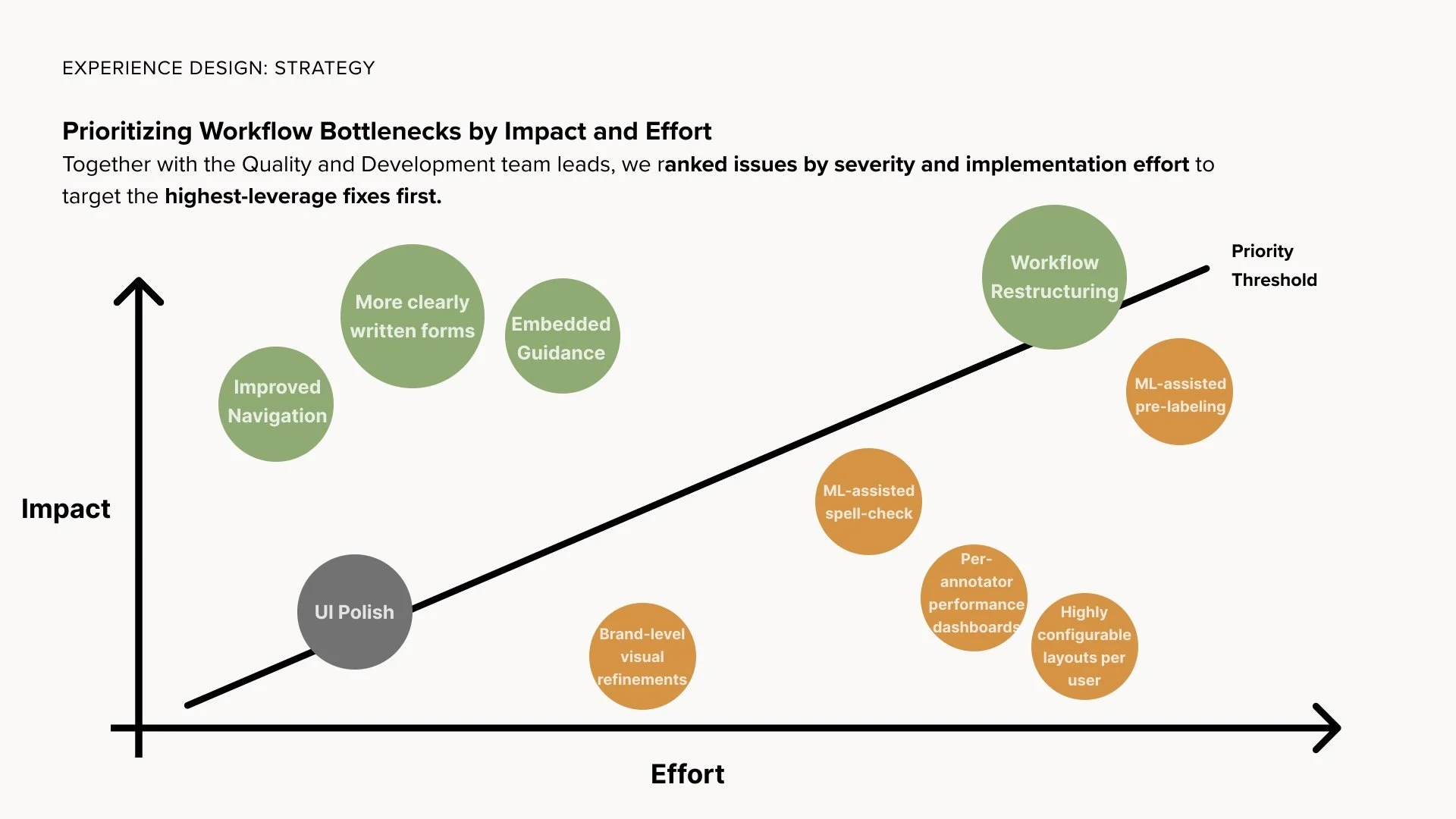
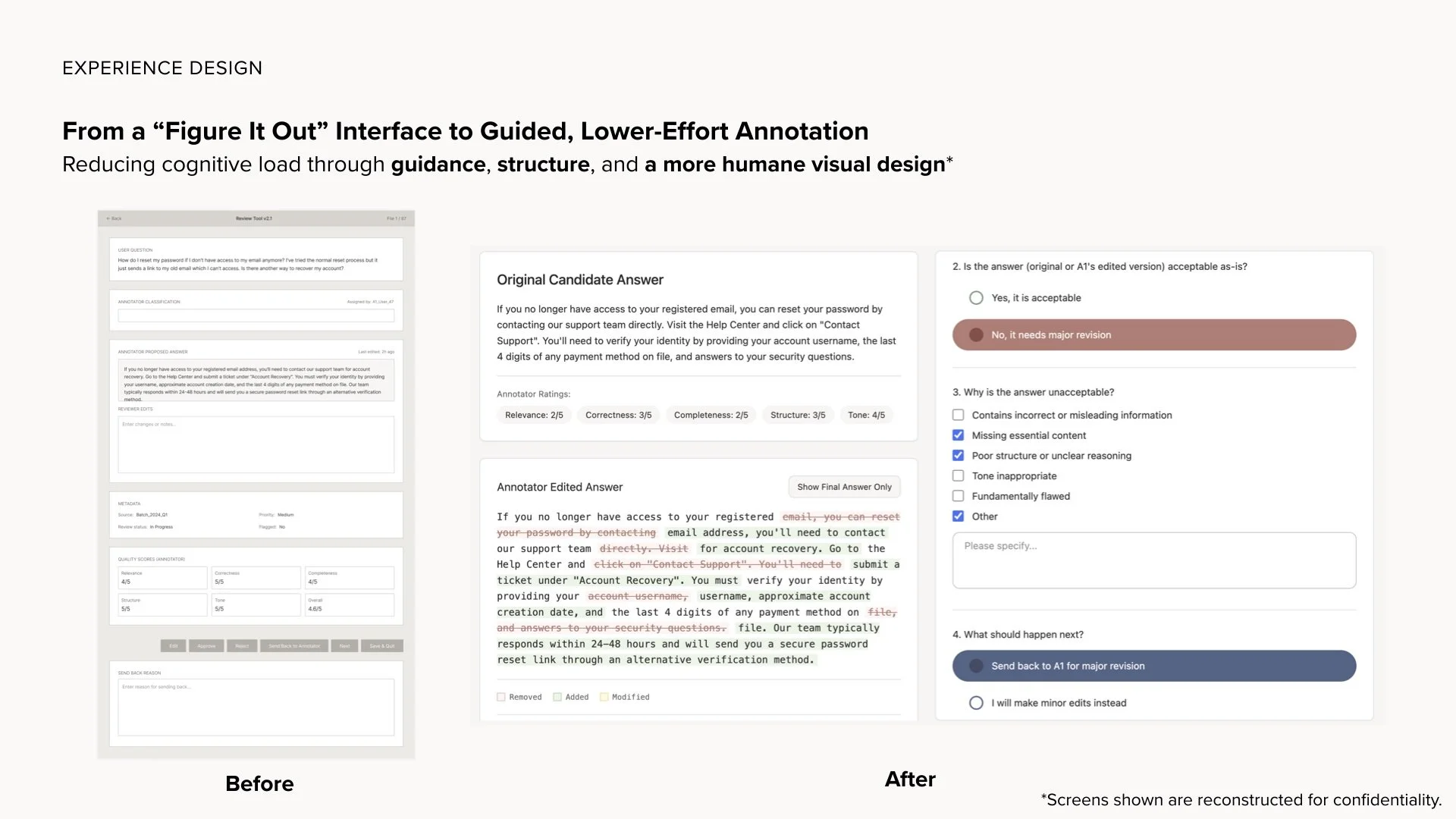
0
Skip to Content
Viiu Katariina Messier
About
Portfolio
Resume
Open Menu
Close Menu
Viiu Katariina Messier
About
Portfolio
Resume
Open Menu
Close Menu
About
Portfolio
Resume